

本期Jesse就带大家来继续了解一下TSDB的应用问题,小伙伴们,让我们直接步入正题吧。
本文仅代表个人观点,如有偏颇之处,还请海涵~

使用TSDB自动检测时序数据的异常情况
现今,每天都有数千亿个传感器产生大量时序数据。公司收集大量数据使得分析和收集洞察力变得具有挑战性。机器学习正在极大地加速时序数据分析,公司希望能够理解并根据他们所积累的时序数据采取行动,以推动重大的创新和改进。有相关分析报告指出,到2025年将有超过1万亿个传感器可用,并生成时序数据。越来越多企业也开始通过SaaS平台的形式将机器学习应用于时序数据,他们通过自动化异常检测和标记过程,然后迭代这些过程以改进数据模型,使其更加有用和高性能。然后服务于航空航天、汽车、电信以及拥有处理大量传感器、遥测和IoT数据的垂直行业。
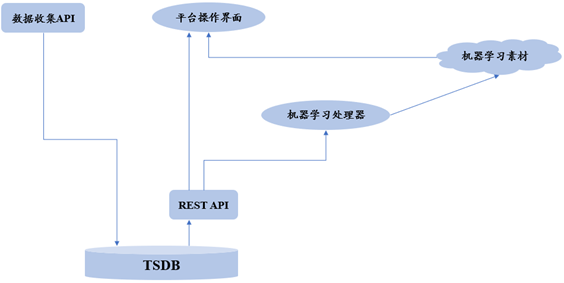
TSDB存储平台核心
异常检测平台一般依赖TSDB作为其数据存储。在使用TSDB之前,很多公司的技术团队也尝试了多种组合,包括关系数据库、NoSQL数据库以及Hadoop和OpenTSDB的组合,它们本质上是一个NoSQL数据库,针对时序数据进行一些调整。但这些解决方案都无法提供处理异常检测平台所需的时序数据的速度和功能。尤其是开源时序数据库,其拥有着活跃的开发者社区,使用他们可以使这些异常检测平台公司的数据科学家能够专注于数据科学和机器学习,而不是时间序列存储。
机器学习挑战
虽然使用TSDB极大提升了平台的存储效率,但在将机器学习应用于时序数据时仍然存在一些挑战。一是连续数据摄取。系统全天候收集数据,这会消耗一定量的处理资源。这就需要我们保持对这种资源消耗的认识,并将其纳入将同时运行的其他流程中,以便他们可以优化连续和非连续工作负载,以提供预期的用户体验。第二个挑战是构建数据模型需要大量数据,这意味着非常大的读取操作。而且,学习过程需要快速,同时可以与其它过程共享资源。这就是REST API的作用,其将任何读取问题整合到一个技术层中,无论在其上运行什么进程或系统。
异常检测
平台为建模和异常检测提供了许多不同的算法,用户可以为他们的数据和业务目标选择最佳选项。然而,无论算法如何,机器学习都需要大量数据。例如,要开始使用一类SVM或隔离森林算法构建异常检测模型,我们至少需要100万个数据点。在60点窗口上计算特征,这是标准的秒或小时级别,会产生15,000个窗口供算法学习。实际上,这并不多,这只是一个系列的因素。包含多个系列的模型需要为每个附加系列增加一百万个数据点。因此,包含三个系列的模型需要300万个数据点才能生成基本模型。有些算法需要更多的数据。长短期记忆算法需要学习原始数据的特征,这意味着在学习阶段需要500万到1000万个数据点。异常检测的一个重大挑战是缺乏数据的底线真实性。因此,可能会出现误报和误报。为了减轻这些异常情况,机器学习算法需要更多关于数据的信息。这就是标签的用武之地。
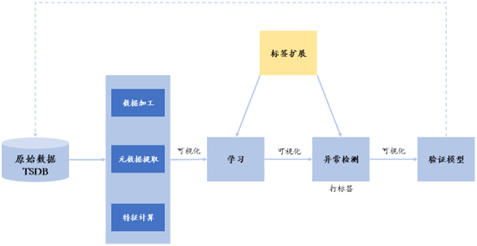
使用机器学习标记数据
标签是数据集上的额外信息。标签帮助算法更多地了解数据,从而使用户能够用它做更好的事情。一种方法是,标签通过从数据集中删除异常来帮助机器学习。这有助于为数据建立更真实的基线。标记大型数据集是一项巨大的时间投入。这也是训练机器学习算法的一个关键方面,数据科学家花费了大量时间标记数据。异常检测平台自动识别异常,使数据科学家更快、更轻松地找到他们需要标记的东西。平台的标签功能还允许用户手动识别数据集中的多个标签。然后它使用AI来检查该系列的其余部分并找到类似的模式。这会生成更多标签,从而产生更多关于系列的信息,以及更准确的数据模型。
在整个异常检测和标记过程中,平台使用查询语言从TSDB查询数据的用户生成数据可视化,因为它可以快速返回大型数据集。TSDB提供的后端功能使公司能够专注于数据科学,而不是基础设施,并提供客户想要的最终用户体验。
本期就到这里我们下期再见。
参与CnosDB社区交流群:
扫描下方二维码,加入CC进入CnosDB社区进入社区交流,CC也会在群内分享直播链接哒



